Parte II: Capas de Activation y capas de Pooling
En este artículo vamos a introducir las capas de Activation (Activación) y Pooling (Agrupación), las redes neuronales convolucionales las introdujimos en la primera parte de esta serie.
Capas de activation
Normalmente, los feature maps (mapas de características) se pasan a través de una capa de activation con el objetivo de incrementar las no-linearidades. Esto compensa las linearidades introducidas por la capa convolucional.
Por ejemplo, una capa convolucional que tiene por objetivo buscar líneas vericales, generará un feature map con píxeles que irán de blanco a negro pasando por varios tonos de gris. La activación (generalmente una ReLU) convertirá los elementos negros a gris, manteniendo sólo los tonos blancos y grises que son los que tienen un valor positivo. De esa forma, los colores cambian de manera más abrupta, incrementando las no linearidades y haciendo que el patrón sea más claro para las capas siguientes.
Capas de pooling
Una limitación de las capas convolucionales es que recueran el punto exacto de la feature (característica) en los datos de entrada. Las imágenes, por ejemplo, muestran al sujeto principal en distintas posiciones, que generaría distintos feature maps. La solución se basa en hacer downsampling (coger menos valores). Una posibilidad es el stride set (conjunto de rectas) como vimos en la primera parte de esta serie. Pero la solución más robusta y común es usar una capa de pooling.
La capa de pooling se aplica sobre cada feature map, devolviéndo el mismo número de output maps. El proceso de pooling es similar al de las capas convolucionales pero sin pesos, en este caso son medias móviles sin estado. Se selecciona una pool de tamaño menor que el feature map de entrada, además del stride y el padding, y se aplica de manera secuencial de izquiera a derecha y de arriba a abajo.
Las capas de pooling pueden ser de tipos diferentes:
- Mean pooling (agrupación por media): se hace la media de los elementos del pool
- Max pooling (agrupación por máximo): se mantiene sólo el valor máximo del pool
- Sum pooling (agrupación por suma): se hace la suma de los elementos del pool
Por lo general se usa el Max pooling
Independientemente del tipo de capa de pooling, las dimensiones de salida serán las mismas. Los parámetros de las capas de pooling son muy similares a aquellos que hemos visto para las capas convolucionales
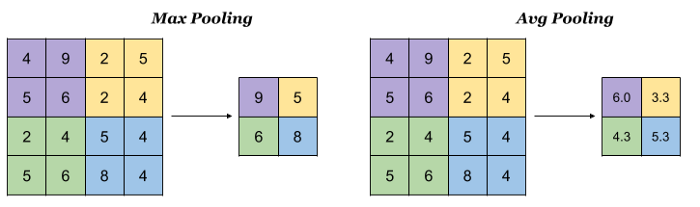
Ejemplo para una entrada de 4×4, tamaño de pool 2×2 y stride de 2, fuente indoml.com
Dimensiones de salida
La implementación en Keras/TensorFlow de la capa de activación se puede definir en la capa convolucional. Siguiendo con el mismo ejemplo que en la primera parte, pero añadiendo una capa de activation ReLU:
tf.keras.layers.Conv2D(filters=5, kernel_size=3, strides=(2,2), padding='valid', activation='relu')Por lo tanto, las dimensiones de salida para la imagen de entrada de 16×8 es:
dimensiones_de_salida = (10, 3, 7, 5)La capa de activación no cambia las dimensiones de salida.
Aplicando una capa de Max pooling con un tamaño de pool (pool_size) de 2, un stride de 2 y el padding a “same” al feature map:
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')Las dimensiones de la altura serían las siguientes:
altura = (altura_feature_map - pool_size + strides) / strides = (3 - 2 + 2) / 2 = 1.5El resultado necesita redondearse hacia arriba porque hemos puesto el padding a “same”.
De la misma manera, para la anchura:
anchura = (anchura_feature_map - pool_size + strides) / strides = (7 - 2 + 2) / 2 = 3.5Por lo tanto, para este ejemplo con padding a “same”, las dimensiones de salida de la capa de Max pooling serán:
dimensiones_de_salida = (10, 2, 4, 5)Para más información sobre las implementaciones de Keras/TensorFlow de las capas convolucionales y Max pooling, consulta los enlaces:



0 Comments