Parte I: Capas convolucionales
Las Redes Neuronales Convolucionales (CNN del inglés, Convolutional Neural Networks) son un tipo de algoritmo de Deep Learning que es capaz de usar datos de entrada multidimensionales como imágenes y detectar y extraer patrones y características. Por estas tazones las CNNs son muy utilizadas en algoritmos que requieren visión por ordenador. En general, las CNNs tiene distintos tipos de capas, los más relevantes son:
- Capas convolucionales
- Capas de activación
- Capas de pooling
- Capas completamente conectadas
Capas convolucionales
Este tipo de capas aplican una serie de filtros a los datos de entrada (generalmente imágenes) para crear un mapa de características que indica la presencia de patrones. Esto se adquiere por medio de convoluciones. La convolución se aplica entre los datos de entrada y una matriz de pesos llamada filtro o kernel, que es más pequeña que los datos de entrada. El filtro se multiplica (por producto escalar) sistemáticamente por todas las dimensiones de los datos de entrada, de arriba a abajo y de izquierda a derecha.
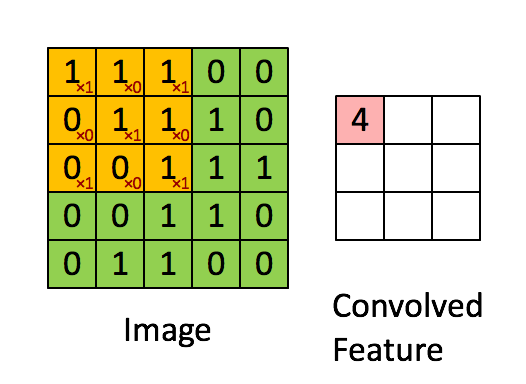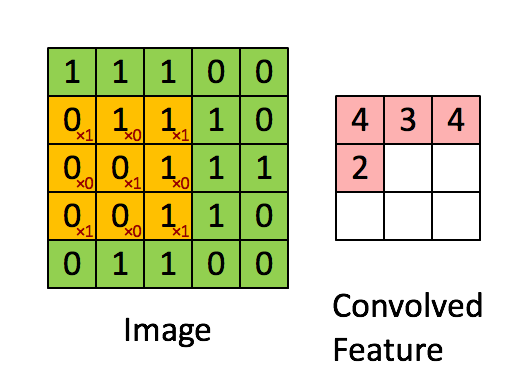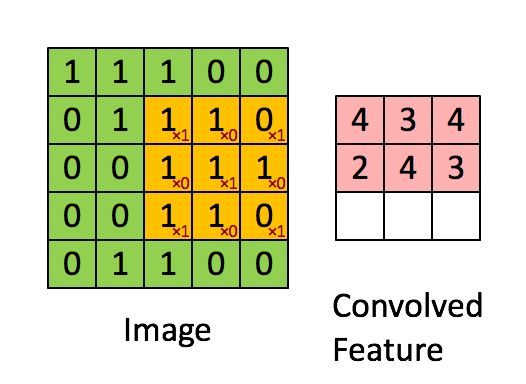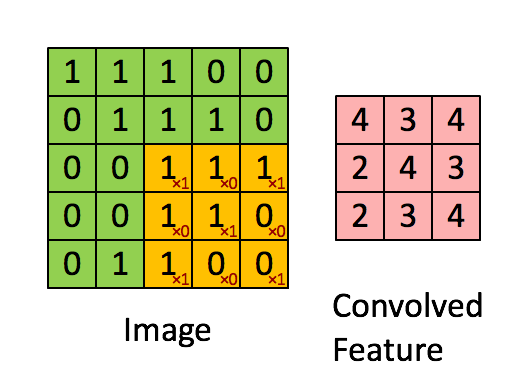
Ejemplo para una entrada de 5×5, filtro de 3×3, con stride 1.
Parámetros
- Se pueden aplicar múltiples filtros, lo cuál determinará la calidad del mapa de características. En Keras y TensorFlow esto se controla a través del argumento de
filtros. - El tamaño del filtro puede controlarse a través del parámetro
kernel_size. Esto afectará a las dimensiones de salida. - La “velocidad” a la que se mueve el filtro se conoce como stride. En Keras y TensorFlow se especifica con el parámetro
strides, que por defecto es 1. Esto afectará a las dimensiones de salida. - Cuando se aplica un stride, la parte que se solapa entre los datos de entrada y el filtro puede que se acabe antes de completar la imagen, para prevenir estas situaciones se suele añadir zero padding para “rellenar” de ceros el input. En Keras y TensorFlow esto se controla con el argumento de
padding. Si el padding no es necesario, este parámetro se ha de poner a “valid”, sino ha de ponerse a “same”.
Dimensiones de salida
Como hemos visto antes, las dimensiones del mapa de características variarán en función de los parámetros de entrada.
Si consideramos 10 imágenes de colores con dimensiones de 16×9 píxeles, los valores de entrada tendrían el siguiente valor:
input_shape = (10, 8, 16, 3)
El primer argumento indica el número de imágenes, el segundo y el tercero son la altura y anchura respectivamente y el último se refiere al número de canales o “profundidad” (en este caso hay tres porque son imágenes a color con RGB (rojo, verde y azul).
Para este ejemplo, imaginemos que los datos de entrada se pasan a la siguiente capa convolucional:
tf.keras.layers.Conv2D(filters=5, kernel_size=3, strides=(2,2), padding='valid')
- El mapa de características tendría una profundidad de 5, esto viene determinado por el número de filtros.
- Las dimensiones de salida se determinan por el tamaño del kernel, el stride y el padding, se pueden calcular usando la siguiente fórmula:
output_width = (image_width - kernel_size + strides) / strides = (16 - 3 + 2) / 2 = 7.5
Dependiendo del padding cambiará la anchura:
"valid": Se redondeará hacia abajo, así que el resultado será 7."same": Se redondeará hacia arriba, así que el resultado será 8.
Pasa lo mismo para la altura:
output_height = (image_height - kernel_size + strides) / strides = (8 - 3 + 2) / 2 = 3.5
Así que en este ejemplo en concreto donde el padding es “valid” (no hay padding de ceros), las dimensiones del mapa de características serán:
output_shape = (10, 3, 7, 5)
Para más información sobre la implementación de capas convolucionales usando Keras/TensorFLow visita:



0 Comments