El clustering K-Means es un algoritmo de Machine Learning unsupervised (de aprendizaje no supervisado) que se usa para hacer clustering (crear grupos similares). Esta técnica se usa para clasificar datos sin etiquetar en K clusters (grupos) basándose en sus similitudes.
El número de clusters K se le pasa como parámetro al modelo. Existen distintas técnicas para determinar su valor óptimo, como veremos en futuros artículos.
K-Means es un algoritmo muy fácil de interpretar. La mejor manera de entenderlo es explicar cómo se entrena.
Cómo se entrena un modelo de K-Means?
- K muestras se eligen al azar como centroides de los K clusters
- Se calcula la distancia de cada muestra a cada centroide
- A cada muestra se le asigna el cluster que tenga más cerca
- Los centroides se recalculan basándose en todas las muestras que pertenecen a cada cluster. La parte de “Means” (media) viene de hacer la media de los clusters para encontrar el centroide
- Se repiten los pasos 2-4 hasta que:
- Los centroides se han estabilizado, sus valores ya no cambian
- Se alcanza el número de iteraciones deseado
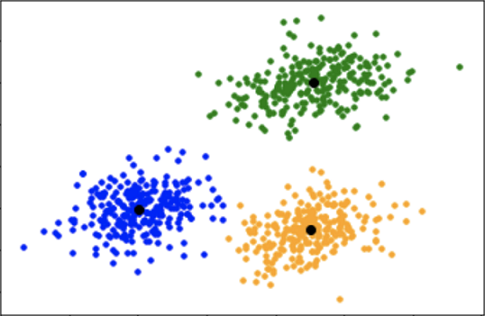
Visualización de un cluster K=3 óptimo
Predicciones
Para hacer predicciones con este modelo, seguiremos los siguientes pasos:
- Se calcula la distancia de la muestra a cada centroide
- Se le asigna el cluster cuyo centroide esté a menor distancia
Ventajas y desventajas
Ventajas
- Fácil de entender e interpretar
- Es más rápido que otros algoritmos de clustering cuando el número de atributos es muy alto
- Produce clusters más concentrados que otros algoritmos
Desventajas
- El número de clusters K no es fácil de determinar. Algunas técnicas como el método del elbow (método del codo) se usan para estimar el valor óptimo
- Los datos han de ser escalados o normalizados, ya que este modelo es muy sensible a la escala de los datos de entrada
- Dependiendo de cómo sean los clusters, puede que no sea el modelo óptimo
- Es muy sensible a la inicialización de los centroides, una mala inicialización puede llevar a clusters no óptimos
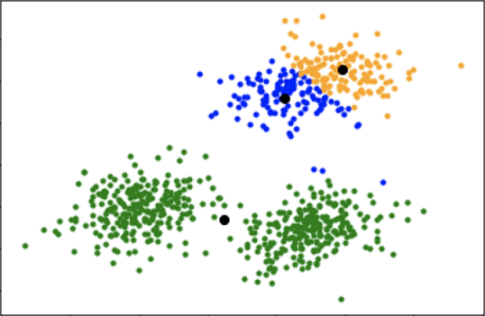
Visualización de un clustering no óptimo por una mala inicialización K=3
Inicialización de centroides
Una manera sencilla de mejorar el clustering es repetir el proceso de entrenamiento varias veces y quedarse con el modelo que tiene la mayor distancia intercluster (entre clusters) y la menor distancia intracluster (dentro de un mismo cluster).
También podemos usar la inicialización K-Means++ que hace una inicialización inteligente de los centroides y mejora la calidad del clustering.
Los pasos para inicializar los centroides con K-Means++ son:
- Se selecciona el primer centroide al azar
- Se calcula la distancia de todos los centroides al centroide seleccionado
- El siguiente centroide será la muestra que más lejos esté de todos los centroides
- Se repiten los pasos 2-3 hasta que tengamos K centroides
Usar K-Mean en Python
Este modelo puede usarse en Python a través de la librería scikit-learn KMeans. Hay que tener en cuenta que la inicialización de los centroides se usa mediante el método de K-Means++.



0 Comments