Ensemble Learning (aprendizaje por combinación) es un método muy usado en Machine Learning que consiste en combinar multiples herramientas. Las herramientas usadas se consideran “modelos base” o “modelos débiles”. Se llaman modelos débiles a aquellos modelos que no tienen un buen rendimiento, por ejemplo, tienen una varianza muy alta o sesgo muy alto.
Hay dos tipos de modelos de Ensemble:
- Homogéneos: Se basan en una combinación de modelos base de un único tipo
- Heterogéneos: La combinación es de modelos base de distintos tipos
Hay tres técnicas para combinar los modelos base:
- Bagging
- Boosting
- Stacking
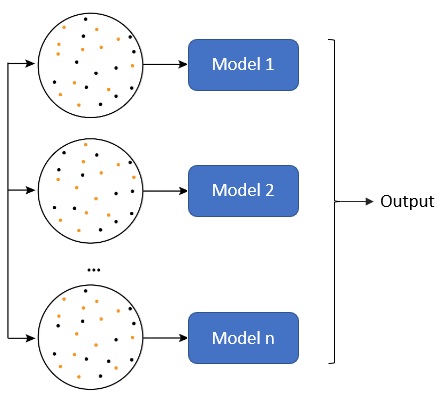
Bagging
Viene del inglés, de “bootstrap aggregating” (agregación por impulso). Usa varios modelos débiles de manera homogénea que tienen una varianza muy alta con el objetivo de reducir esa varianza. A cada modelo débil se le entrena con un dataset que se consigue cogiendo un número arbitrario de muestras aleatorias e independientes del dataset de entrenamiento.
Tras eso, se usan distintos métodos para sacar la inferencia:
- Regresión: La inferencia es la media de la predicción de cada modelo
- Clasificación: podría ser por votación absoluta, en cuyo caso la inferencia elegida es por la que más modelos han votado, o por votación ponderada, donde la inferencia se basa en una media ponderada de las predicciones de cada modelo
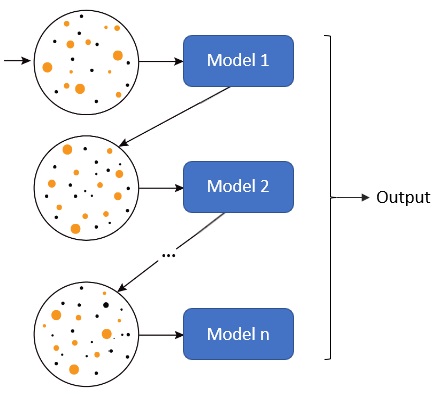
Boosting
Es un método que usa varios modelos débiles homogéneos de baja varianza y sesgo alto con el objetivo de reducir el sesgo. Los modelos son entrenados de manera secuencial, cada modelo se entrena dándole una mayor importancia a las muestras que peor resultado han dado en los modelos anteriores.
Hay 2 maneras de hacer la inferencia:
- Media ponderada de las predicciones de los modelos
- Suma ponderada de las predicciones de los modelo
Los algoritmos más populares que se basan en boosting son:
- AdaBoost
- Gradient Boosting
- XGBoost
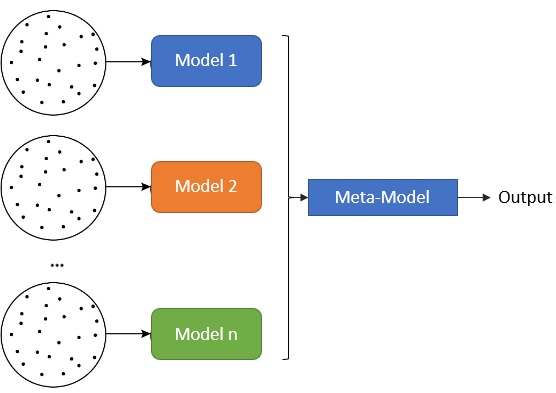
Stacking
Usa modelos débiles heterogéneos y un meta-modelo. El meta-modelo usa las predicciones de los modelos débiles como datos de entrada, lo cual hace que se agreguen y que sea el meta-modelo el que haga la inferencia final.
Estos modelos se entrenan generalmente usando un entrenamiento basado en k-fold, lo que significa que el dataset de entrenamiento se divide en k grupos. k-1 de esos grupos se usan para entrenar a los modelos débiles y el restante se usa para entrenar al meta-modelo. Este proceso se repite de manera iterativa hasta obtener un buen nivel de entrenamiento.



0 Comments