Regresión lineal es un tipo de algoritmo supervisado de Machine Learning que se usa para hacer regresiones. Las regresiones son una técnica que se usa para predecir datos de salida continuos que pueden ajustarse a una recta. Este algoritmo es muy sencillo y muy fácil de entender.
La siguiente gráfica representa una regresión lineal con una única variable independiente:
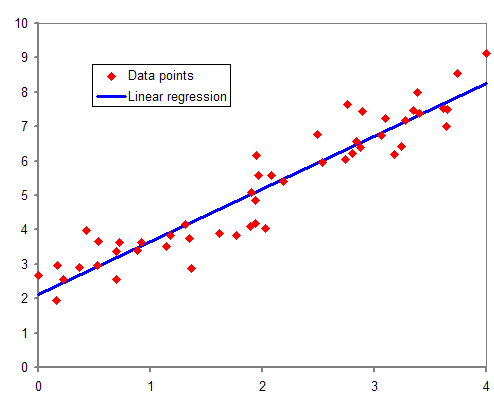
Ejemplo de regresión lineal con una sola variable independiente. Fuente: Wikipedia
Hay dos tipos de regresión lineal:
- Regresión lineal simple: el caso más sencillo, sólo hay una única variable independiente. La ecuación del modelo es la siguiente:
$$ y = B_0 + B_1 x_1 $$
- Regresión lineal múltiple: en este caso hay más de una variable independiente, este es el caso generalizado que se describe con la siguiente fórmula:
$$ y = B_0 + B_1 x_1 + … + B_n x_n $$
Entrenamiento
El modelo se entrena estimando el valor de los coeficientes B que mejor se ajusten a los datos de entrada. Para ello, se debe minimizar la función de coste, la más común para regresión lineal corresponde a la suma de los residuos al cuadrado (la diferencia entre los valores de y y las predicciones ŷ):
$$ J = \frac{1}{n} \sum_{n=1}^{n} (y_i – \hat{y_i})^ 2 $$
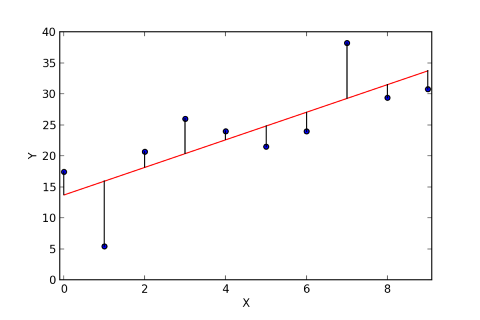
Ejemplo de residuos en una regresión lineal. Fuente: Wikipedia
Hay varias maneras de minimizar esta función:
Mínimos cuadrados ordinarios
Esta solución trata a los datos de entradas como si fueran una matriz y usa operaciones de álgebra lineal para calcular los coeficientes óptimos.
Este método es capaz de encontrar los óptimos y es muy rápido, por contra usa todos los datos disponibles y, por lo tanto, se necesita memoria suficiente para tener todo el dataset cargado.
Scikit-Learn usa este método en la librería de LinearRegression.
Gradiente Descendiente
Este método se basa en calcular de manera iterativa la dirección del error e ir actualizando el valor de los coeficientes hasta minimizar la función de coste.
Este es el método recomendado si el dataset es demasiado grande para tenerlo cargado en memoria.
Scikit-Learn usa este método en la librería de SGDRegressor.
Preparar los datos
Para que el modelo de regresión lineal funcione correctamente, los datos de entrada deben ser adecuados. A continuación se lista una serie de cosas a tener en cuenta:
- Los datos deben ser numéricos ya que los modelos de regresión lineal no aceptan categorías
- Los datos de entrada deben ser escalados o estandarizados, de manera que todos tengan un valor similar. Esto impedirá que el modelo les de más peso a categorías con valores mayores.
- Los outliers (valores atípicos) se tienen que quitar del modelo antes de entrenarlo
- Los valores missing (ausentes) se han de quitar o darles algún valor
- Hay que quitar atributos que tengan una alta correlación con otros para prevenir la correlación
- Hay que tratar los atributos que no estén linealmente correlados con la variable independiente
- Hay que quitar las variables que no den información para reducir el ruido
- Para incrementar la fiabilidad del modelo, los atributos deben de seguir una distribución normal o Gausiana, de no ser así habría que hacer otras transformaciones como podrían ser las logarítmicas



0 Comments