Parte I: Valores faltantes y deducción de tendencia
Los datos de series temporales son una secuencia de observaciones registradas a intervalos de tiempo regulares y que son usados comúnmente en múltiples campos, como finanzas, economía e ingeniería. Sin embargo, los datos de series temporales a menudo pueden contener ruido, valores atípicos, valores faltantes y otras anomalías que pueden afectar el análisis y la interpretación de los datos. Por lo tanto, la limpieza de los datos es un paso importante en el proceso de análisis de series temporales.
Este artículo proporcionará una descripción general completa de los pasos involucrados en la limpieza de datos de series temporales. Estos pasos, en el orden lógico en el que normalmente se realizarían, son:
- Tratar valores faltantes
- Quitar tendencia
- Quitar estacionalidad
- Comprobar la estacionariedad y hacerlo estacionario si fuera necesario
- Normalizar los datos
- Eliminar valores atípicos
- Suavizar los datos
Este artículo también proporcionará una guía general para limpiar datos de series temporales y resaltará la importancia de utilizar un enfoque adecuado para limpiar datos de series temporales. Tenga en cuenta que, según sus datos, deberá omitir algunos pasos o agregar, modificar o agregar otros.
Primeros pasos
Usaremos un conjunto de datos de Kaggle que contiene los valores de la producción mensual de cerveza en Australia desde 1956 hasta 1995 .
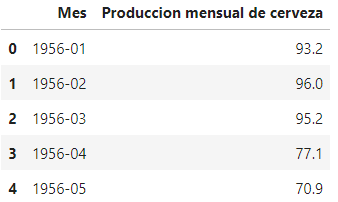
El primer paso después de importar los datos es inspeccionarlos. Podemos comenzar comprobando el encabezado (las 5 primeras filas de datos) del conjunto de datos.
# Importar librerías requeridas
import pandas as pd
import numpy as np
# Leer el dataset
df = pd.read_csv("/monthly-beer-production-in-austr.csv")
# Comprobar el tipo de datos
print(df.dtypes)
# Mostrar las 5 primeras filas
df.head()
Dos cosas a observar:
- La fecha no tiene el tipo de datos correcto, debe ser datetime .
- El índice no es la fecha del dataframe, y este es un requisito importante cuando se trata de datos de series temporales.
Entonces, el siguiente paso sería convertir la fecha a datetime y establecerla como índice.
# Convertir la columna Mes a datetime
df['Mes'] = pd.to_datetime(df['Mes'], format='%Y-%m')
# Establecer como índice la fecha
df = df.set_index('Mes')
# Convertir el dataframe a series
df_cerveza = df['Produccion mensual de cerveza']Una vez hecho esto podemos graficarlo:
# Importar librerias requeridas
import matplotlib.pyplot as plt
# Visualizar datos
df_cerveza.plot(figsize=(14,6))
plt.xlabel('Fecha')
plt.ylabel('Produccion mensual de cerveza')
plt.grid()
plt.show()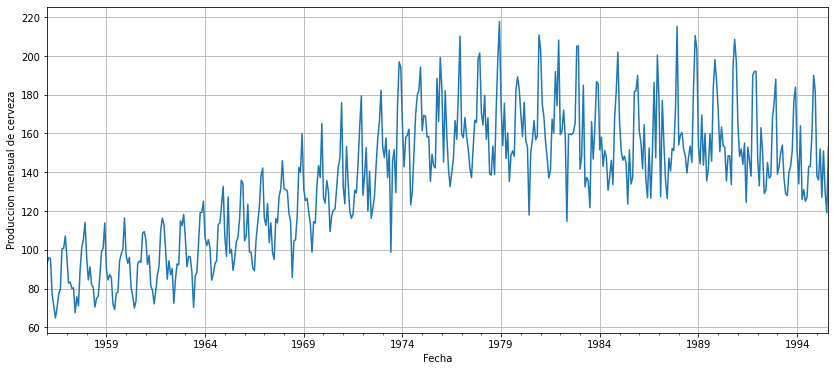
Intentemos resumir las principales preocupaciones de los datos simplemente echando un vistazo rápido a la gráfica anterior:
- No es estacionario
- Parece haber un componente estacional.
- Hay una tendencia y una varianza creciente.
- Parece que hay valores atípicos
Estos son algunos de los problemas que tendremos que abordar en el proceso de limpieza de datos.
Limpieza de datos
Tratar valores faltantes
Necesitamos comprobar si faltan valores o no.
# Comprobar que no haya valores faltantes
df_cerveza.isna().sum()
Tenemos suerte esta vez, no hay valores faltantes.
Si tuviéramos, podríamos proceder de formas diferentes:
- Imputación: estos métodos completan los valores faltantes con valores estimados. Algunos métodos de imputación populares incluyen la imputación de valor constante, la imputación de media, mediana o moda, y el relleno hacia adelante o hacia atrás.
- Interpolación: estos métodos utilizan funciones matemáticas para estimar los valores faltantes en función de los valores de las observaciones circundantes. Los más populares son la interpolación lineal, la interpolación polinomial y la interpolación spline.
- Modelado predictivo: los métodos de modelado predictivo utilizan algoritmos estadísticos o de machine learning para construir un modelo para predecir los valores faltantes en función de los valores de otras variables. Algunos métodos populares de modelado predictivo incluyen K-Nearest Neighbors, regresión, árboles de decisión, bosques aleatorios (random forests) y redes neuronales.
Es importante elegir un método apropiado para tratar los valores faltantes en función de las características y los requisitos específicos de los datos. En algunos casos, puede ser necesaria una combinación de métodos para obtener los mejores resultados. Mostramos a continuación cómo nos deshacemos de los valores faltantes utilizando algunos de los métodos descritos anteriormente:
# Imputación de valor constante
df_cerveza = df_cerveza.fillna(0)
# Imputación de la media
df_cerveza = df_cerveza.fillna(df_cerveza.mean())
# Imputación de valor previo
df_cerveza = df_cerveza.bfill()
# Interpolación lineal
df_cerveza = df_cerveza.interpolate(method='linear')Pero, como se mencionó antes, esto no es necesario con los datos actuales.
Quitar tendencia
La mayoría de los modelos, como ARIMA , requieren que los datos sean estacionarios. La estacionariedad se logra cuando los datos tienen una media, una varianza y una covarianza constantes.
El primer paso para lograrlo es eliminar la tendencia. La tendencia se puede eliminar utilizando diferentes métodos. Consulte a continuación los más comunes:
- Diferenciación: restar las observaciones de un período de tiempo anterior para estabilizar la media de la serie a lo largo del tiempo.
- Descomposición: desglose de la serie temporal en sus componentes de tendencia, estacional y residual y eliminando el componente de tendencia.
- Promedios móviles: calcular el promedio de las observaciones durante un número fijo de períodos de tiempo y restarlo de cada observación.
- Ajuste polinómico: ajuste de una curva polinomial a los datos de la serie temporal y sustracción de la serie original para eliminar la tendencia.
- Filtros de tendencia: utilizando filtros como el filtro de Hodrick-Prescott o Kalman para eliminar el componente de tendencia.
- Transformaciones logarítmicas: tomar el logaritmo de los datos de la serie temporal para reducir la magnitud de la tendencia y estabilizar la varianza de la serie.
- Transformaciones de Box-Cox: transformación de los datos de la serie temporal mediante una transformación de potencia para estabilizar la varianza y hacer que la tendencia sea lineal.
Según los requisitos específicos y las características de los datos, una técnica puede ser más adecuada que otra. En algunos casos, se requerirá más de un método.
Para nuestro ejemplo, mostraremos el primero, que es uno de los más utilizados. Después de tomar la primera diferencia de los datos, debemos eliminar la primera fila de nuestros datos. Esto se debe a que no podemos obtener la diferencia del primer elemento ya que no hay otro valor antes. Por lo tanto, aparece como NaN (Not a Number) y simplemente se puede descartar.
# Toma la primera diferencia para quitar tendencia
df_cerveza= df_cerveza.diff()
# Quita la primera fila con NaN
df_cerveza= df_cerveza.dropna()
# Grafica los datos para ver el resultado
df_cerveza.plot(figsize=(15,5))
plt.xlabel('Fecha')
plt.ylabel('Ratio de producción de cerveza')
plt.grid()
plt.show()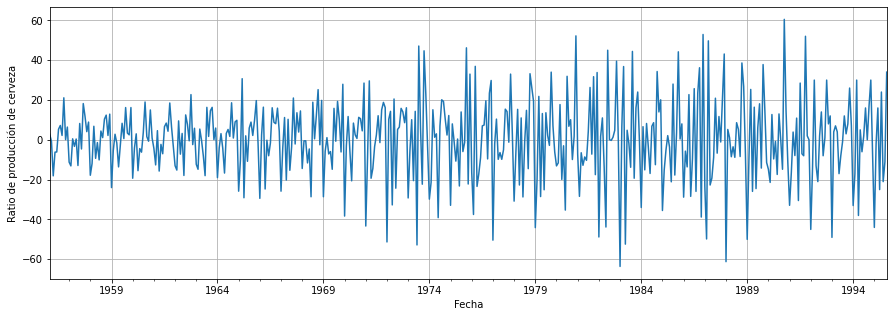
Observamos que la media ahora es aproximadamente constante alrededor de cero. Sin embargo, aún queda otro problema por resolver: la varianza no constante o creciente .
Podríamos usar algunas de las transformaciones vistas antes. sin embargo, utilizaremos un enfoque más intuitivo en su lugar. Para hacer frente a la variación en continuo aumento a lo largo de los años, podríamos imponer una variación constante para cada año. Veamos cómo podemos lograr esto en Python.
# Calcula la variancia anual (equivalente a desviación típica)
annual_variance = df_cerveza.groupby(df_cerveza.index.year).std()
mapped_annual_variance = df_cerveza.index.map(
lambda x: annual_variance.loc[x.year])
# Estandarizar la varianza anual
df_cerveza = df_cerveza / mapped_annual_variance
# Mostrar resultado
df_cerveza.plot(figsize=(15,5))
plt.xlabel('Fecha')
plt.ylabel('Ratio de producción de cerveza estandarizada')
plt.grid()
plt.show()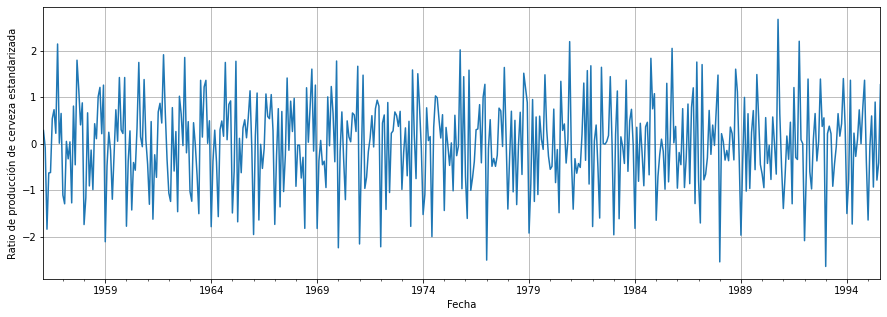
Finalmente podemos ver cómo nuestros datos tienen una varianza y una media constantes. ¡Estamos un paso más cerca de lograr la estacionariedad!
Puedes acceder al cuaderno en nuestro repositorio:

Para ejecutarlo ahora mismo, haga clic en el icono de abajo:
¡En el próximo artículo veremos cómo verificar y eliminar la estacionalidad!



0 Comments