Part II: Activation and Pooling Layers
The activation layers and pooling layers of the Convolutional Neural Networks (CNN) will be introduced, following the first part of this series where the convolutional layers were explained.
Activation Layers
Normally, the feature maps are passed through an activation layer with the purpose of increasing non-linearities. This makes up for the possible linearities introduced during the convolutional layer.
For example, a convolutional layer that aims for searching for vertical lines will generate a feature map with pixels ranging from white to black passing through many shades of grey. The activation (generally a ReLU) would turn the black elements into grey, keeping only the white and grey tones, which are the ones that carry the positive value. In this way colors change now more abruptly, increasing the non-linearities and making the pattern more recognizable for the following layers.
Pooling Layers
A limitation of the convolutional layers is that they record the exact location of the features in the input. Images can display the main subject in different positions, which would lead to different feature maps. A solution to this is down-sampling. One possibility was the stride set in the convolutional layer as seen in the previous part of this series. But a more robust and common method is to use a pooling layer.
It is applied to each feature map, resulting in the same number of output maps. The process of pooling is similar to one in the convolutional layers, but without weights, in this case, they are just stateless sliding windows. A pooling operation or pool is selected with a size smaller than the input feature map, in addition to a stride and padding; and it is sequentially applied from left to right and from top to bottom.
The pooling layers can be of different types:
- Mean pooling: the elements within the pool are averaged
- Max pooling: the maximum of the elements is kept
- Sum pooling: the elements within the pool are added together
Generally, the Max Pooling layer is selected.
Regardless of the type of pooling layer, output dimensions will be the same. The parameters that set up the pooling layers are similar to the ones seen before for the convolutional layers.
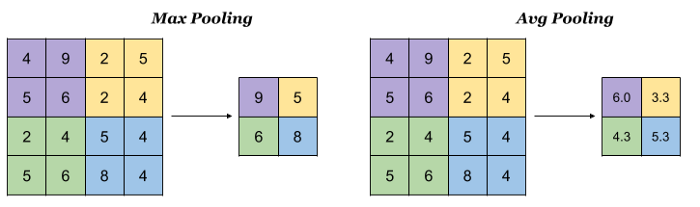
Example for input size 4×4, pool size 2×2 and strides 2.
Source: indoml.com
Output dimensions
The Keras/TensorFlow implementation of the activation layer can be specified in the convolutional layer. For instance, following the same example as in the first part, but adding a ReLU activation layer:
tf.keras.layers.Conv2D(filters=5, kernel_size=3, strides=(2,2), padding='valid', activation='relu')As seen in the previous article, the output shape from that convolutional layer for a color input image of 16×8 pixels was:
output_shape = (10, 3, 7, 5)The activation layer does not change the dimensions of the output.
Following, if a Max Pooling layer with a 2 pixels pool size, a stride equal to 2 and padding set to “same” is applied to the feature map:
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')The resulting output would have the following dimensions:
output_height = (feature_map_height - pool_size + strides) / strides = (3 - 2 + 2) / 2 = 1.5The result needs to be rounded up because of having the padding set to “same”.
Similarly for the width:
output_width = (feature_map_width - pool_size + strides) / strides = (7 - 2 + 2) / 2 = 3.5Therefore, for this example, in which the padding is set to “same”, the dimensions of the output from the max pooling layer will be:
output_shape = (10, 2, 4, 5)Further information on the Keras/TensorFlow implementation of the convolutional layers and max pooling layers can be found below:



0 Comments