Part I: Convolutional Layers
Convolutional Neural Networks (CNN) are a kind of deep learning algorithms that can take multidimensional data such as images as input and detect and extract patterns or characteristics within it. CNNs have been proven to be very useful in Computer Vision.
These networks apply different kinds of layers to extract information from the image. The most relevant ones are:
- Convolutional layers
- Activation layers
- Pooling layers
- Fully-Connected layers
Convolutional layers
These layers apply a series of filters to the input data (generally images) to create feature maps that summarize the presence of patterns. They do so by means of convolutions. This operation is performed between the input data and a matrix of weights called filter or kernel that is smaller than the input.
This filter is multiplied (dot product) systematically across the dimensions of the input data, by being overlapped to the input from left to right and from top to bottom.
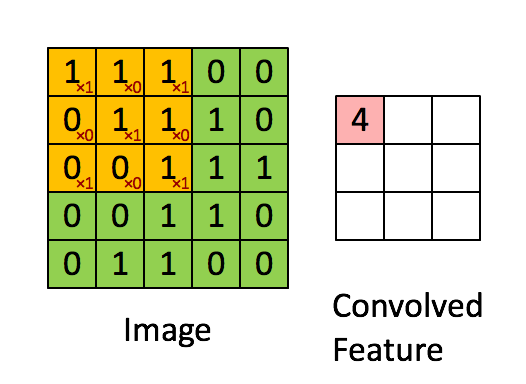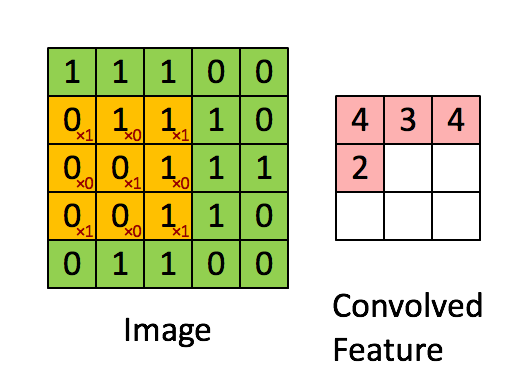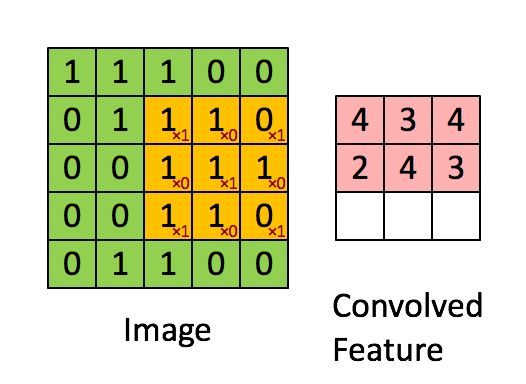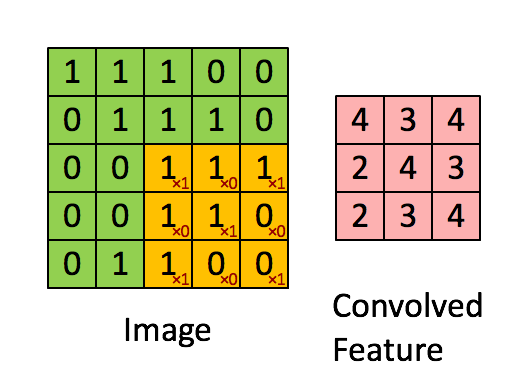
Example for input size 5×5, filter size 3×3 and strides 1.
Parameters
- Multiple filters can be applied, which will determine the depth of the output feature map. In Keras and TensorFlow, it is controlled through the
filtersargument. - The size of the filter can be controlled through the
kernel_sizeparameter. It refers to the size of the overlapping patch or matrix. It will affect the dimensions of the output. - The step with which the filter is applied is called the stride. It downsamples the data. In Keras and TensorFlow it can be specified through the
stridesargument, which is by default 1. This also affects the dimensions of the output feature map. - When a stride is added, the overlapping could finish before reaching the end of the input dimensions. In this case, some rows and columns will be ignored. To prevent this scenario, zero padding could be evenly added around the input. In Keras and TensorFlow, this can be controlled through the
paddingargument. If the desired behavior is the first one, then this argument can be unspecified or set to“valid”; otherwise, it must be set to“same”.
Output dimensions
As seen before, the output feature map will have different dimensions depending on the selected parameters for the convolutional layer.
If we consider ten color images with dimensions 16×8 pixels, the input data would have the following shape:
input_shape = (10, 8, 16, 3)The first argument indicates the number of images, the second and third arguments refer to the height and width respectively, and finally, the last one indicates the number of channels or depth (three for color images because of the three RGB channels, and one for black and white images).
For this example, we will consider that the input data go through the following convolutional layer:
tf.keras.layers.Conv2D(filters=5, kernel_size=3, strides=(2,2), padding='valid')- The output feature map would have a depth of 5, determined by the number of filters.
- The dimensions of the output will be determined by the kernel size, the stride and the padding. For example, the output width dimension can be calculated as:
output_width = (image_width - kernel_size + strides) / strides = (16 - 3 + 2) / 2 = 7.5Depending on the set padding the width will differ:
"valid": it will be rounded down, so the result will be 7."same": it will be rounded up, yielding 8.
This is done also for the height:
output_height = (image_height - kernel_size + strides) / strides = (8 - 3 + 2) / 2 = 3.5Therefore, for this example, in which the padding is set to “valid” (no zero padding applied), the dimensions of the output feature maps will be:
output_shape = (10, 3, 7, 5)Further information on the Keras/TensorFlow implementation of the convolutional layers can be found here:

Check here for the continuation.


0 Comments