This is a special article. We will try to get a model that could be able to predict whether the price of Bitcoin will increase or decrease the next day. However, we will use a different approach today, we will ask ChatGPT. We will pretend we don’t know anything (or very little about Python, Time Series and Machine Learning). We will then see if Data Scientists can be replaced in the near future or not.
Let’s start by giving ChatGPT the instructions on what we want to achieve:

I tried to guide ChatGPT by mentioning that I wanted to get the data from yfinance, a Python library to get financial data such as the Bitcoin price.
The first step according to ChatGPT is to install the required libraries, which makes sense.
Install necessary libraries: - Install yfinance: pip install yfinance - Install other required libraries such as pandas, numpy, scikit-learn, and matplotlib.
Stay up-to-date with our latest articles!
Subscribe to our free newsletter by entering your email address below.
Then it says that we need to import the necessary libraries. Let’s inspect what libraries is ChatGPT suggesting.
Import the necessary libraries:
import yfinance as yf
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt- yfinance: the library that will allow us to import the Bitcoin price history
- pandas and numpy: basic libraries to manipulate data
- train_test_split: a scikit-learn function to split the data into training and testing sets
- RandomForestClassifier: this one is interesting, it is planning to reframe the task into a classification problem and it will use a powerful Ensemble Learning method such as Random Forest.
- accuracy_score: another scikit-learn library to assess the accuracy of the model.
- matplotlib: a well-known library to plot graphs.
It seems like ChatGPT is going in a sensible way. Let’s continue…
Get Bitcoin price data using yfinance:
# Define the ticker symbol for Bitcoin
ticker = "BTC-USD"
# Get historical data from yfinance
data = yf.download(ticker, start="2015-01-01", end="2023-07-09")It guided us on how to import the Bitcoin price data, from 2015 until today. Let’s display the variable data:
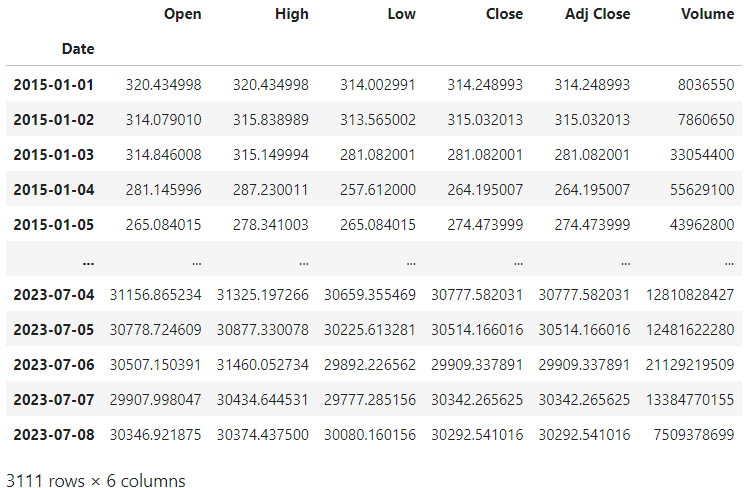
We can see that the data ranges from the 1st of January 2015 until the 8th of July 2023. It includes the opening price, the highest and lowest price during the day, the closing price, the adjusted closing price and the volume during the day.
Let’s continue:
Preprocess the data:
# Create a new column for the target variable indicating price increase or decrease
data["PriceDiff"] = data["Close"].shift(-1) - data["Close"]
data["Target"] = np.where(data["PriceDiff"] > 0, 1, 0)
# Drop NaN values
data.dropna(inplace=True)
# Select relevant features (e.g., Close price) for training
features = ["Close"]
X = data[features]
y = data["Target"]
It is time to process the data. It seems that it is going to continue with the closing price as the main indicator, which is a common approach in univariate stock forecasting. The first step ChatGPT takes is shifting the data by one day and calculating the difference in price between one day and the previous one. This is what will be used as a target variable by the model during the training process. It then drops any missing values. Finally, it gets the closing prices as independent variables. This means that ChatGPT is transforming the Bitcoin price data into a univariate supervised problem. This is one of many paths it could have selected. Let’s see if it is indeed an effective path.
Split the data into training and testing sets:
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)Time to split the data into training and testing sets. However, there is a big issue here, we shouldn’t shuffle the data when working with time series. In order to see if previous data has representative patterns that can be useful for the future, we need to consider only data up to a particular time point for training the model, and from that point to test it. We can amend the code in the following way:
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, shuffle=False
)
Let’s continue with the code ChatGPT suggested:
Train a Random Forest Classifier:
# Create and train the Random Forest Classifier
clf = RandomForestClassifier(
n_estimators=100, random_state=42
)
clf.fit(X_train, y_train)It was time of training the model with our training data. No issues here. Let’s carry on doing some predictions:
Make predictions:
# Make predictions on the testing set
y_pred = clf.predict(X_test)This is also an expected step when training an ML model. We use the testing set to predict the target variable. So the next logical step would be to compare it with the testing set labels, which is what ChatGPT suggested:
Evaluate the model:
# Calculate accuracy score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)If we run this code we get that the accuracy of this model is slightly over 50%:
Accuracy: 0.5176848874598071
This is not good enough. That could be because of multiple reasons. See some of them below:
- Bitcoin price is unpredictable.
- The model is not good enough and another more sophisticated and complex model capable of capturing more patterns could have been used.
- We could have engineered some features such as moving averages or some technical indicators.
- Only the previous price was considered.
Let’s finish with the last step in ChatGPT’s instructions:
Visualize the results:
# Plot the Bitcoin price and predicted price increase or decrease
plt.figure(figsize=(12, 6))
plt.plot(data.index,
data["Close"],
label="Bitcoin Price")
plt.scatter(data.iloc[y_test.index].index,
data.iloc[y_test.index]["Close"],
color="red",
label="True Increase" if 1 in y_test.values else "True Decrease")
plt.scatter(data.iloc[y_test.index].index,
data.iloc[y_test.index]["Close"],
color="green",
label="Predicted Increase" if 1 in y_pred else "Predicted Decrease")
plt.xlabel("Date")
plt.ylabel("Price")
plt.legend()
plt.show()This unfortunately did not work, so I requested something different, as I was more interested in seeing if the prediction was right or not, rather than splitting it into true increase or decrease.

Certainly! Here's an updated version of the visualization that highlights incorrect predictions in red and correct predictions in green:
# Plot the Bitcoin price and highlight incorrect and correct predictions
plt.figure(figsize=(12, 6))
plt.plot(data.index, data["Close"], label="Bitcoin Price")
# Get the indices of incorrect and correct predictions
incorrect_indices = y_test[y_test != y_pred].index
correct_indices = y_test[y_test == y_pred].index
# Plot incorrect predictions in red
plt.scatter(data.loc[incorrect_indices].index, data.loc[incorrect_indices]["Close"],
color="red", label="Incorrect Prediction")
# Plot correct predictions in green
plt.scatter(data.loc[correct_indices].index, data.loc[correct_indices]["Close"],
color="green", label="Correct Prediction")
plt.xlabel("Date")
plt.ylabel("Price")
plt.legend()
# Set x-axis limits to the last 2 months of data
last_month = data.index[-1] - pd.DateOffset(months=2)
plt.xlim(last_month, data.index[-1])
plt.show()After adding some additional lines to improve the visualization format, here you have the final outcome:
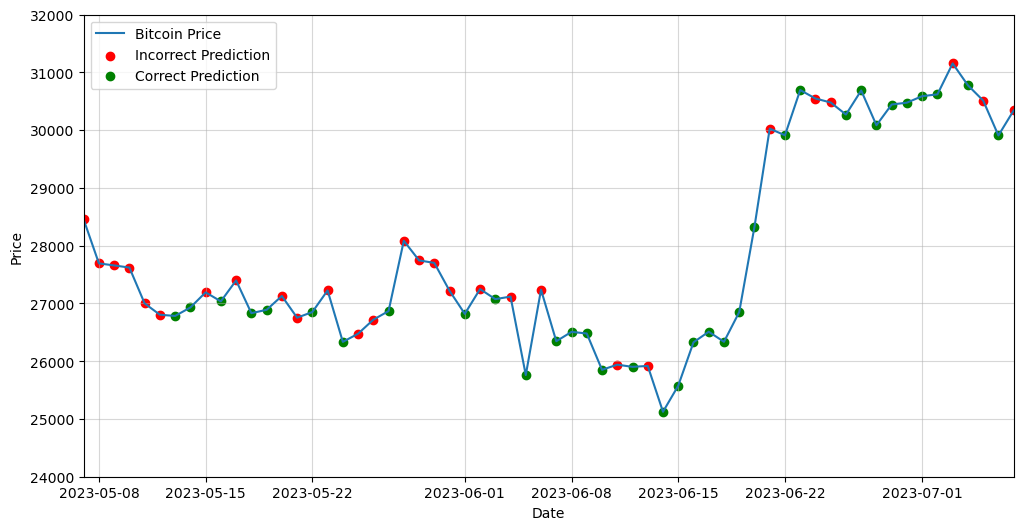
Conclusions
ChatGPT is a powerful tool that can help us start a programming task. It is also able to generate complex code. However, at this particular moment, it is not able to grasp the particularities of the problem and decide the best approach to follow in each case.
For example, Random Forests is designed to handle multivariate data. Therefore, it would have been useful to keep the opening price or the volume for example. Also, it could have been suggested to add some technical indicators to improve the accuracy since they are widely used in trading.
My conclusion is that ChatGPT is an amazing tool if you know about a topic since it can assist you and help you improve and speed up your coding, however, it is still far from being able to replace a Data Scientist.



0 Comments