Decision Trees are a fundamental model in machine learning used for both classification and regression tasks. They are structured like a tree, with each internal node representing a test on an attribute (decision nodes), branches representing outcomes of the test, and leaf nodes indicating class labels or continuous values. Decision trees are intuitive and mimic human decision-making processes, making them popular for their simplicity and ease of interpretation.
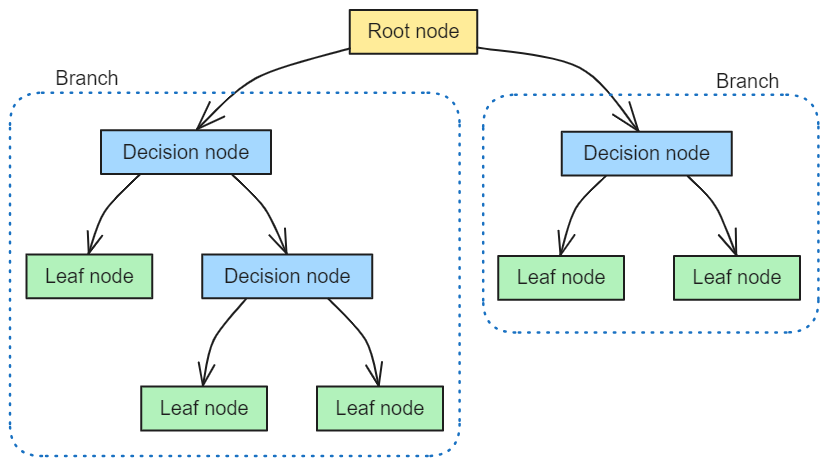
How does it work?
The goal of this algorithm is to create a model that accurately predicts the target value by learning a series of ‘if-then’ rules following a tree-like structure. The algorithm initiates by selecting the best attribute to split the data, chosen based on its ability to reduce impurity in the target variable (e.g., using measures like Gini impurity or information gain). This process of splitting is recursively applied to each child node. The tree grows in depth until a stopping criterion is met, which could be a set minimum number of samples in a leaf node or reaching a maximum depth of the tree. This methodology ensures that the tree is constructed in a way that maximizes the predictive accuracy while reducing overfitting through the stopping criteria.
Advantages and Limitations
Like any other algorithm, Decision Trees has some advantages that make it suitable for particular cases. However, there are also some limitations that one must be aware. This would allow us to change to another algorithm that could be more suitable for our data or problem.
Advantages
- Interpretability: Easy to understand and visualize.
- Handles Both Types of Data: Can process both numerical and categorical data.
- No Need for Scaling: Works well without feature scaling or normalization.
- Handles Non-Linearity: Effectively captures non-linear relationships.
- Robust to Collinearity: Not affected by multicollinearity in features.
- Automatic Feature Selection: Tends to prioritize the most informative features.
Limitations
- Overfitting: Prone to overfitting, especially with complex or deep trees.
- Instability: Small changes in data can lead to different splits, affecting the model’s stability.
- Biased to Dominant Classes: In classification, they can be biased towards dominant classes.
- Difficulty with Certain Tasks: Struggles with tasks that require understanding the relationships between features, like XOR problems.
Train your model
Following, we provide a code that illustrates the implementation of a Decision Tree algorithm in Python using the scikit-learn library. Initially, it imports necessary libraries and loads a dataset from a CSV file. The dataset is then split into features (X) and the target variable (y). Following this, a Decision Tree model is created — a DecisionTreeClassifier for classification tasks. This model is trained (or “fitted”) on the dataset, enabling it to learn patterns from the features and their corresponding target values. Finally, the trained model is used to make predictions on the dataset.
from sklearn.tree import DecisionTreeClassifier
import numpy as np
import pandas as pd
# Load the data
data = pd.read_csv("data.csv")
X = np.array(data.drop(['target'], axis=1))
y = np.array(data['target'])
# Create the Decision Tree classifier
model = DecisionTreeClassifier()
# Train the model
model.fit(X, y)
# Predict using the trained model
predictions = model.predict(X)For regression tasks, where the target variable is continuous, the code would be similar but would utilize DecisionTreeRegressor instead.
Ensemble Methods Using Decision Trees
Decision Trees are a basic algorithm that is frequently combined to create more powerful and complex models. Some common examples of these ensemble methods are:
- Random Forest: Combines multiple decision trees through bagging to improve stability and accuracy.
- XGBoost: An implementation of gradient boosting machines that uses decision trees as base learners.
- CatBoost: Optimized for categorical data, uses an advanced form of gradient boosting with decision trees.
These ensemble models get many of the advantages of Decision Trees:
- Robustness to Collinearity: Maintained across these ensemble methods.
- No Need for Feature Scaling: Ensemble methods also do not require feature scaling.
- Handling Non-Linear Relationships: Enhanced ability to capture complex relationships.
- Handling of Different Data Types: Retained ability to process both numerical and categorical data.
Additionally, they get additional ones thanks to addressing some of the limitations of Decision Trees:
- Reduced Overfitting: Techniques like bagging in Random Forest and boosting in XGBoost and CatBoost reduce the risk of overfitting.
- Improved Stability: Aggregating predictions across multiple trees reduces the impact of instability in individual trees.
- Enhanced Performance on Complex Tasks: Ensemble methods generally perform better on tasks that are challenging for a single decision tree.
- Handling Imbalanced Data: Better equipped to handle imbalanced datasets, especially with appropriate tuning.
In summary, decision trees are a versatile and intuitive machine learning model with distinct advantages like ease of interpretation and robustness to collinearity. However, they have limitations like overfitting and instability. Ensemble methods like Random Forest, XGBoost, and CatBoost build upon decision trees to overcome some of these limitations, offering improved accuracy, stability, and performance on complex tasks.



0 Comments