K-Means is an unsupervised Machine Learning algorithm used for data clustering. It is a technique employed to classify unlabelled data into a number K of clusters or groups based on their similarities.
The number of clusters K is an input to the model. There exist different techniques to determine its optimal value that will be discussed in future articles.
It is a very simple and easy-to-interpret algorithm. It can be better understood when explaining its training procedure.
How is a K-Means model trained?
- K data points are chosen randomly as centroids of the K clusters.
- The distance of each data point to each centroid is computed.
- Each data point will be assigned the cluster whose centroid is the closest.
- The centroids are recalculated based on the data points that belong to each cluster. The “means” part of the model name comes from averaging the data to find the centroids.
- Repeat steps 2 to 4 until:
- The centroids have stabilized, meaning that there is no change in their values.
- The specified number of iterations has been achieved.
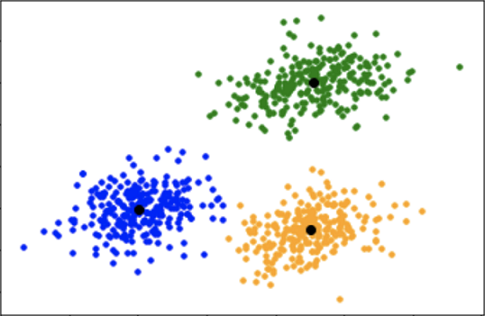
Visualization of optimal clustering. K = 3
How can we predict the cluster a new data point belongs to?
In order to get the predictions from this model, we will need to follow a similar process to the one followed during training.
- Calculate the distance to each K centroid.
- Assign the cluster whose centroid is the closest.
What are its advantages and disadvantages?
Advantages
- Easy to understand and interpret.
- It is faster than other clustering algorithms when the number of features is very large.
- It produces tighter clusters than other clustering algorithms.
Disadvantages
- The number K of clusters is not easy to determine. Some techniques such as the elbow method can be used to estimate its optimal value.
- The data needs to be scaled or normalized as this model is very sensitive to the scale of the different features.
- It may not be suitable for particular geometrical shapes of the data clusters.
- It is sensitive to the initialization of the centroids. A poor initialization could lead to a poor clustering.
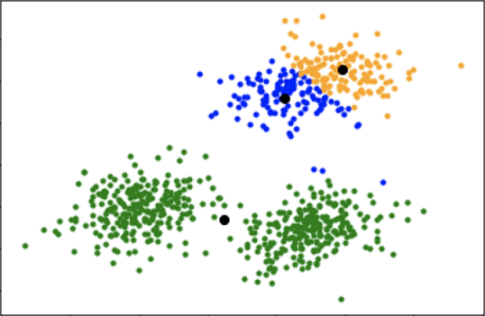
Visualization of a poor clustering due to a poor initialization of centroids. K = 3
Centroids initialization
One way of improving the clustering is repeating the K-Means training process several times and selecting the model that has the largest intercluster distance and the smallest intracluster distance.
Also, we can use the K-Means++ initialization to ensure a smarter initialization of the centroids and improve the quality of the clustering.
The steps for initializing the centroids with the K-Means++ algorithm are the following:
- Randomly pick the first centroid.
- Calculate the distance of all data points to the selected centroid.
- The next centroid is chosen as the data point that is the farthest from the nearest centroid.
- Repeat steps 2 and 3 until selecting the K centroids.
How can I use it in Python?
Finally, this model can be used in Python thanks to the scikit-learn library KMeans. It is worth mentioning that the centroids initialization is set by default to the K-Means++ algorithm.



0 Comments